Sorry folks – this isn’t supposed to be click bait. Yeah, like “text prediction” is ever going to be click bait that breaks the internet…
You’ll never guess what happened after the user type in ‘th’
Or how about…
The 5 most commons words that get predicted if you type ‘hi’
Enough of the corny jokes.
So, because I know and like Ruby – especially the automated testing part of it – I built a real text prediction service using the ideas from this post this using Ruby on Rails. There is a bunch of plumbing that is not relevant to the actual text prediction side of things which you can find in the GitHub repo. The general gist is that a user types something into a text box on a web page, an ajax call is fired off that sends that off to a rails controller. It has a quick look in a database and fires back some (clickable) suggestions. It looks like this:
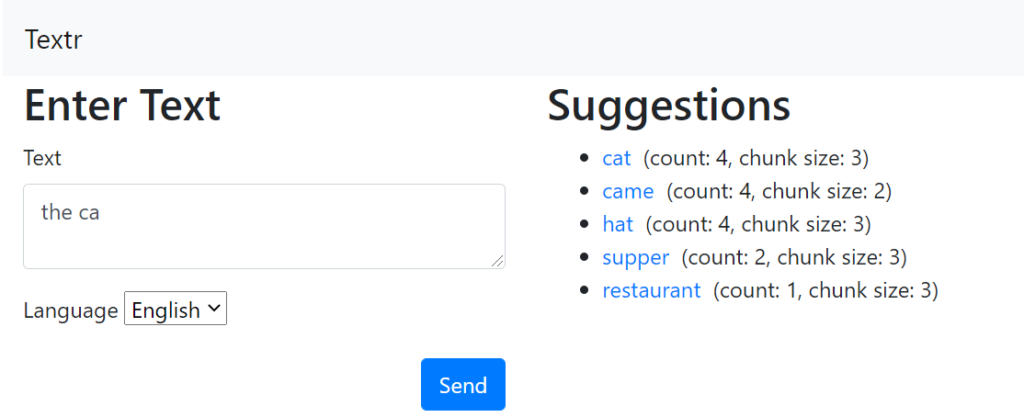
I’ll explain what’s going on in this screen shot down below.
Driving Algorithm
In this post, we are going to look at what the “quick look in the database” algorithm is:
def suggest
# handle null input
return { candidates: [] } if @text.strip.empty?
# format the suggestions for candidate chunks
format(candidate_chunks)
endThe first line is straight-forward. First of all, we handle the situation when there is not actually any text provided by the user to make a prediction against.
Then we go to work – first going to the database to get the most likely word completing chunks, and then formatting those database rows to make it easier to suggest individual words. The heart of the algorithm lies in selecting these candidate chunks from the database, so let’s refresh our memories on what a chunk is first before looking at the algorithm.
Chunks
Essentially, chunks are collections of contiguous tokens – along with a count of how many times they appear in the database. What does that mean? Well, given a sentence, say, “the cat in the hat”, we break it down into chunks of various sizes. In this implementation, we are using chunks of 2 to 8. For a chunk size of three (that is three tokens – with a space counting as a token), and a single sentence, we might have the following chunks in our database:
| Chunk Text | Token IDs | Count |
|---|---|---|
| the_cat | 1, 2, 3 | 1 |
| _cat_ | 2, 3, 2 | 1 |
| cat_in | 3, 2, 4 | 1 |
| _in_ | 2, 4, 2 | 1 |
| in_the | 4, 2, 1 | 1 |
| _the_ | 2, 1, 2 | 1 |
| the_hat | 1, 2, 5 | 1 |
We’d also store the size (i.e. number of tokens) of the chunk (in this case 3) and probably language ID and/or user IDs as well – so that we can do text prediction for multiple languages and users (since every user has their own style). The count column above is set to 1 for every row, but of course, in a data set with more than one short sentence in it, the number of times “_the_” appears in any given English language training set would grow rather large. If we’d set our chunk size above to 2 (instead of 3), then we’d have a count of 2 for the chunk “the_” because this chunk appears twice in our training sentence. And of course, the larger the chunk size, the lower the counts. But how do we use these things?
Candidate_Chunks
At heart, this algorithm is fairly straightforward:
def candidate_chunks
candidate_token_ids = []
# Get chunks that match the prior tokens and the current word
candidate_chunks = chunks_by_prior_tokens_and_current_word(
prior_token_ids_from_text, candidate_token_ids
)
# Extract the token ids for potential words from those chunks
candidate_token_ids += token_id_candidates_from_chunks(
candidate_chunks.to_a
)
# If we got our MAX_SUGGESTIONS then we're done
return candidate_chunks if candidate_token_ids.size == MAX_SUGGESTIONS
# Get more chunks but without using the current_word
candidate_chunks + chunks_by_prior_tokens_only(
prior_token_ids_from_text, candidate_token_ids
)
end
Since we need to make sure we are only returning MAX_SUGGESTIONS of candidate words, we need to keep track of each unique token_id we find. They are stored in candidate_token_ids. Although my phone only shows three, I want to show users up to five suggestions – mostly so that i can see what is going in. Once we have our quota of five, we can stop bugging the database.
We then need to go and get some some chunks of tokens that match what the user is currently typing along with the tokens they have just typed. That’s what chunks_by_prior_tokens_and_current_word does. It will only return a maximum of MAX_SUGGESTIONS suggestions. If the user is currently typing in a word that the system has never seen before, then this method will not return anything. We pass into this method all the tokens that we have found before the current word that is being type with the method prior_token_ids_from_text which I’ll explain in a moment.
From this list of candidate chunks, we grab the last token in each chunk (since this is the token we are going to show to users). So, if one of our chunks had these tokens in it [12,2,23,2,45] then we would be interested in whatever word the token 45 corresponded to.
If we haven’t got MAX_SUGGESTIONS of possible tokens, then we go for looking for the best tokens to complete the words they typed before – but not the word that they are currently typing. And since we don’t want any tokens that have already been suggested, we pass in the list of token suggestions already found as the candidate_token_ids argument. We add any of these newly found candidate chunks to what we found before and return them.
You’ll see that we are giving priority to tokens that match what the user is currently typing, and only then do we go looking for possible sentence-completing words. These suggestions are unlikely to be very useful to the user since they don’t match what they are currently typing. But, there might be typos, so we’ll show them anyway…
You’ll have likely realised that all the database complexity happens in the chunks_by_prior_tokens_and_current_word and chunks_by_prior_tokens_only methods. They are fairly similar to each other, so we’ll only look at chunks_by_prior_tokens_and_current_word. But first, let’s look at prior_token_ids_from_text.
Prior_token_ids_from_text
Here’s the code:
def prior_token_ids_from_text
max_tokens_to_return = ChunkAnalyser::CHUNK_SIZE_RANGE.max - 1
# get the token ids
prior_token_text = Token.split_into_token_texts(@text)
# remove last piece of text, unless it's a space or punctuation
last_token_text = prior_token_text[-1]
prior_token_text = prior_token_text[0..-2] unless
last_token_text.punctuation? || last_token_text.whitespace?
# add any new tokens just found to the database
prior_token_text = prior_token_text.join
token_ids = Token.id_ise(prior_token_text, :by_word)
# return (at most) the most recent 8 of those tokens
token_ids[(token_ids.length > max_tokens_to_return ?
-max_tokens_to_return : - token_ids.length)..]
endThe first line tells us how many prior tokens we are interested in analysing. I have gone with 8 (including spaces), but it might be interesting to experiment with this – or do it without spaces – since a) spaces are by far the most common tokens in any given text and b) storing chunks with spaces in them more or less doubles the database size.
After that, we need to remove the last word the user typed – since that is what we are trying to predict.
The next step is to get the numeric ID of each token as it appears in our database. Our overall algorithm is looking for token_ids and not actual pieces of text, so these IDs are important. The Token.id_ise(text) method converts each text token to an ID from the database.
Finally, we return the last 8 (at most) of these token IDs.
After that interlude, let’s get back to the method that actually looks for candidate chunks based on what the user is typing now and what they have typed before.
Getting into the Database
Here is the code:
# Returns chunks candidates that match current user input ordered by occurrence
#
# @param prior_token_ids token IDs that have been entered so far
# @param candidate_token_ids candidate token IDs that have already been found
# @return chunks that match the search parameters
#
# Returns empty array if the current word doesn't match any known tokens
def chunks_by_prior_tokens_and_current_word(prior_token_ids,
candidate_token_ids = [])
return Chunk.none if candidate_tokens_for_current_word.empty?
candidate_token_ids_for_current_word =
candidate_tokens_for_current_word.to_a.map(&:id)
# construct a where clause for each of the possible completing words
token_ids_where = candidate_token_ids_for_current_word.map do |token_id|
"token_ids = ARRAY#{prior_token_ids + [token_id]}"
end
token_ids_where = token_ids_where.join(' OR ')
token_ids_where = " AND (#{token_ids_where} )" unless token_ids_where.blank?
# Grab the candidate chunks from the database
candidate_chunks = Chunk.where("language_id = :language_id #{token_ids_where}",
language_id: @language_id)
.exclude_candidate_token_ids(candidate_token_ids, prior_token_ids.length + 1)
.limit(MAX_SUGGESTIONS - candidate_token_ids.size)
.order(count: :desc).to_a
# Add any new candidate tokens to the list
candidate_token_ids += get_token_id_candidates_from_chunks(candidate_chunks)
# If we got MAX_SUGGESTIONS or we're out of prior_tokens, then we're done
return candidate_chunks if candidate_token_ids.size == MAX_SUGGESTIONS || prior_token_ids.size.zero?
# Do it again, but for one less prior token
candidate_chunks + chunks_by_prior_tokens_and_current_word(prior_token_ids[1..],
candidate_token_ids)
end
This is the most complex method in the system – and it could do with a refactor…
But the basic idea is that:
- We find all the tokens in the database that could possibly match the word the user is currently typing. So, if the user is typing ‘th’ then, depending on our training set, then possible tokens might be ‘the’, ‘that’, and ‘therapeutic’. The more of the word that the user has typed in, the smaller the number of candidates.
- If there aren’t any tokens that match what the user is currently typing, then we can exit right away.
- We build a
WHEREclause for the chunks table that finds all the chunks with theprior_token_idsand these potential completing tokens. - We only return at most
MAX_SUGGESTIONSnumber of chunks – less any that we have found before. - We show the most commonly occurring suggestions first.
Once we have some candidate chunks, we grab the final token_id from each one. If we have MAX_SUGGESTIONS, then we can return the candidate chunks. But if not, then we drop the first token_id from the list of prior_token_ids and do the same search again. Yes, this is a recursive function.
One extra piece of complexity is that each time we call this function, we need to pass in the list of candidate_token_ids we have already found so that we aren’t adding duplicates to the list. That is what the exclude_candidate_token_ids method is doing to alter the WHERE clause – it is excluding from the candidates any rows that have a token_id we have already found. And of course, once we have run out of prior_token_ids, then we return – even if we don’t have MAX_SUGGESTIONS candidates.
Other method, chunks_by_prior_tokens_only, is pretty similar to this one – but the where clause is slightly different since it doesn’t need to look for chunks that end with what the user is currently typing.
Results
So, although it’s not super-complex, it’s not a trivial piece of code either. Building out these methods with automated tests to look for the edge cases was a pretty helpful thing to do. Let’s look again at the output:
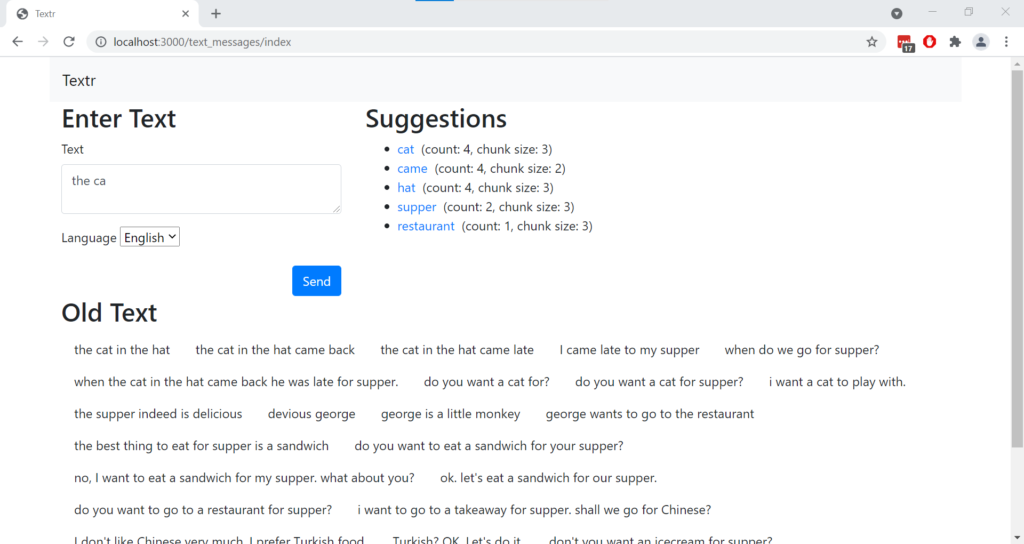
Thee are three main parts to the screen:
- A place for users to enter their text.
- Suggestions (with the most likely at the top) and some analysis next to it.
- All the previous text that has been entered into the system – the training text.
Lets unpack the suggestions part of the output.
I have typed in a few “cat in the hat” type training phrases as you can see. When I enter “the ca” then, as expected, the first suggestion the system is giving me is “cat”. Next to the word “cat”, it is telling me there is a count of 4 and a chunk size of three. This is telling me that, so far, the 3-token chunk “the cat” has been entered 4 times. From a scan of the text, you can see that is true.
Next on the list is the word “came” – which seems like an odd choice to come after “the “. True – but as there are no other 3-chunk completions (like “the canoe” or “the canal”) in the training set, the system is looking for 2-chunk completions. i.e. things that complete ” ca”. And you can see from the training data that ” came” appears 4 times. Sure, ” cat” also appears a lot of times, but those aren’t counted here since we have already found “cat” as a potential completion. Maybe the algorithm should be amended to give even more weight to the word “cat”.
The next suggestion is “hat”. Now, “hat” does not start with a “ca” – but since the only chunks that match “the ca” are “the cat” and ” came”, the algorithm has stopped using the word “ca” and is now just looking for the most likely tokens to come after “the “. The word “hat” occurs the most (4 times) in our training data, so that is why it shows up. Same for the next two words on the list: “supper” and “restaurant”.
Final Thoughts
I have played with this a little bit and – as expected – the more input data, the better (and more useful) the suggestions. At time of writing, there are only 31 training sentences, with a total of 111 different tokens (mostly words, plus spaces and other punctuation). These create a total of 1720 chunk combinations when analysing chunk combos of length 2 to 8. At other times, I have added a fair bit more data into the database, and the number of chunks increases rapidly – although the actual database size is pretty compact. But since row limits for free PostgreSQL server are usually pretty restricted (e.g. Heroku’s is 10,000), it’s not going to be possible to demo this for real on the internet with a free service. Also, from a performance stand-point, it’s hard to see this being a great solution. Even though each key-press generates only only one network roundtrip, on the server we generate quite a large number of database calls. Although the calls are relatively fast and database caching helps, there are still quite a lot of database calls. Some custom in-memory data structure rather than a PostgreSQL is likely going to be way faster – but I was lazy and just wanted to use a database.
That said, as a proof of concept, the idea seems to work pretty well as is – although it doesn’t really handle typos too well, and that is a critical feature for text prediction on a smart phone. So, before moving onto a neural net solution, in a future post, we might look at this with a larger number of tokens (i.e. words) in the database, different styles of English (I’m looking at you King James) and perhaps try it with a different language to see how well the idea works for an agglutinating (i.e. endings-heavy) language like modern Turkish.
One Reply to “Actual, Actual Text Prediction”